
はじめましての方は初めまして、ちちぷいでご存じの方はお世話になっております。風祭小枝です。
今回はStableDiffusionに革命を起こしたControlNetについて取り扱いたいと思います。
この記事でわかること:ControlNetのPreprocessor/modelについて
注意点:すでにControlNet自体の使い方を知っている人向けです。導入方法や各種ボタン・パラメータについての説明はここでは行いません。
皆さんの中には、画像生成のガチャ要素を減らすためにControlNetを扱っている方もいるかと思いますが、こんなことを感じている方がいらっしゃるのではないでしょうか…?
Preprocessorが多すぎる!
実装当初は数種類しかなかったPreprocessor(プリプロセッサ)ですが、今はなんと52種類あります!(2023年9月19日現在/ControlNet v1.1.40の場合)
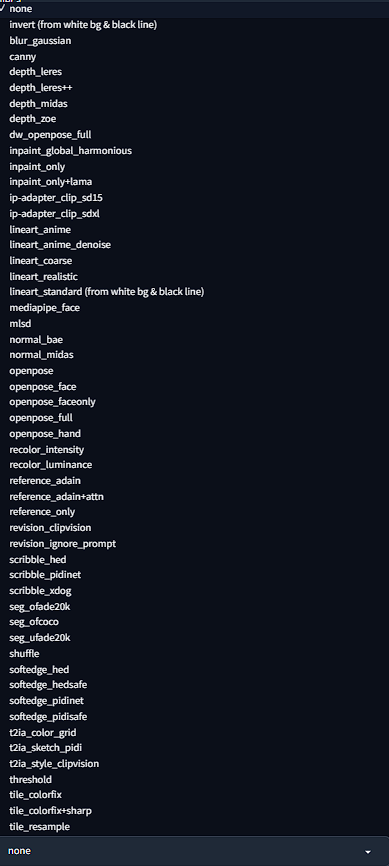
今回はこのあまりにも多いプリプロセッサをすべて紹介していきたいと思います!
ちなみに今回の記事を制作するにあたってこちらを参照しています。英語や技術用語にアレルギーが無い人はこちらの方が参考になる……かも?

まずはカテゴリ(Control Type)で見てみる
まずはカテゴリで見てみましょう。
現在は以下の18カテゴリ(Control Type)で分けられています。
- Canny
- Depth
- NormalMap
- OpenPose
- MLSD
- Lineart
- SoftEdge
- Scribble/Sketch
- Segmentation
- Shuffle
- Tile/Blur
- Inpaint
- InstructP2P
- Reference
- Recolor
- Revision
- T2I-Adapter
- IP-Adapter
結構多いです。これを使いこなせている人はすごいですね。次は各項目の解説をしていきます。
各項目を見る前に
各項目を見る前に、以下の注意点がございます。
- 基本的にはSD1.5ベースの内容になります。SDXLの場合は都度お知らせします。
- Control Weightはすべて1で生成します。ご自身で使用する際は適切な値を設定してください。
- Starting Control Stepは0、Ending Control Stepは1で設定しています。
- 生成された画像はシード値が固定されていません。数回生成して、一番よかったものを採用しています。
- プロンプトは言及がない限り、以下を使用しています。青:プロンプト・赤:ネガティブプロンプト
(finely best quality illustration:1.2), (white background:1.25), (kawaii girl:1.1), (1girl, solo:1), Craftsman made contour, Refined contour, sexsual skin, coquettish skin, (soft smile:0.7), Sophisticatedly detailed eyes
EasyNegative, negative_hand-neg_2, (worst quality, low quality:1.4), ((realistic:0.4) lip (nose:0.4) tooth, rouge, lipstick, eyeshadow:1), (dusty sunbeams:1), (abs, muscular, rib:1.2), (text, title, logo, signature:1), (depth of field, out of focus:1.4), (bad anatomy:1), (wip, sketch:0.8), (animal ears, animal:1.05), manga, comic, magazine, title text, animal, animal ears
いよいよ各項目を見ていこう!
かなり長いので、すべてを見る予定の方は休み休みでご覧ください。
モデルをダウンロードするときは下記からどうぞ


Canny
Canny法と呼ばれるエッジ検出アルゴリズムです。
| Preprocessor | Model |
|---|---|
| canny | control_v11p_sd15_canny |
| invert (from white bg & black line) |
難しいことは置いといて、結果の画像を見てみましょう。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| canny |  |  |  |
| invert (from white bg & black line) |  |  | なし |
cannyはエッジ(輪郭と思ってもらえばいいです)を検出し、それをお手本に画像を生成する方式。invertは線画をControlNetで扱える形にする処理ですね。処理後の画像を別のmodelに通すことで生成に影響を与えることができます。
Depth
深度マップです。撮影対象との相対距離を色強度に変換した画像を作ります。
| Preprocessor | Model |
|---|---|
| depth_leres | control_v11f1p_sd15_depth |
| depth_leres++ | |
| depth_midas | |
| depth_zoe |
こちらはプリプロセッサが4種類存在します。それぞれ見てみましょう。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| depth_leres | |  |  |
| depth_leres++ | |  |  |
| depth_midas | |  |  |
| depth_zoe | |  |  |
どれが良い悪いとかは正直ありません。leres/leres++は深度調節のパラメータがあるので、そういうのが面倒って人にはmidasかzoeをおすすめします(上記画像はパラメータ調節していません)。ちなみにmidasは自動運転、zoeは3D物体検出に使われるアルゴリズムです。
手などを微修正するときに便利なDepth Libraryなどの拡張機能も存在します。
NormalMap
ノーマルマップです。表面の凹凸の変化を表現する手法です。
| Preprocessor | Model |
|---|---|
| normal_bae | control_v11p_sd15_normalbae |
| normal_midas |
こちらは2種類ですね。いまさらですが、プリプロセッサの種類は、アルゴリズムのバリエーションが増えたことによるものです。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| normal_bae | |  |  |
| normal_midas | |  |  |
見てみると、baeの方はいい感じなんですが、midasの方はあまりいい画像が生成されませんでした。midasの方は閾値の設定などがシビアなので、使うならbae一択になりそうです。
OpenPose
姿勢推定アルゴリズムです。ControlNetを世に知らしめたのはこれのおかげといってもいいですね。
| Preprocessor | Model |
|---|---|
| dw_openpose_full | control_v11p_sd15_openpose |
| openpose | |
| openpose_face | |
| openpose_faceonly | |
| openpose_full | |
| openpose_hand |
初期から実装されているだけあってプリプロセッサの数も多いです。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| dw_openpose_full |  | 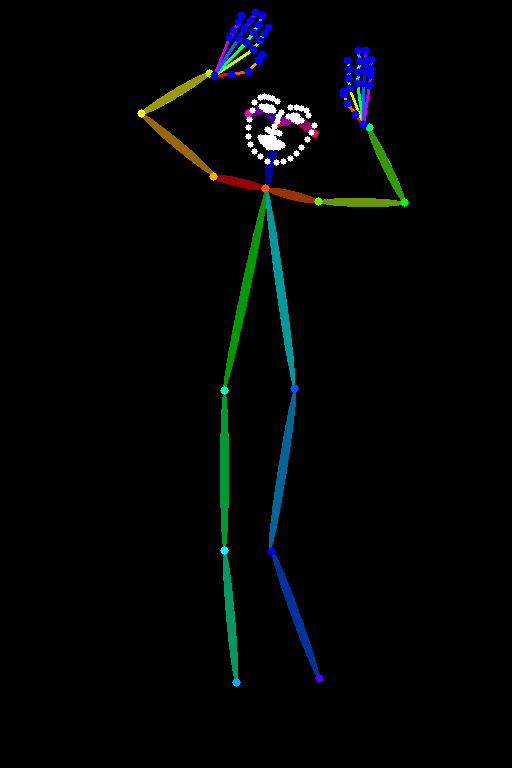 |  |
| openpose | |  |  |
| openpose_face | |  |  |
| openpose_faceonly | |  |  |
| openpose_full | | 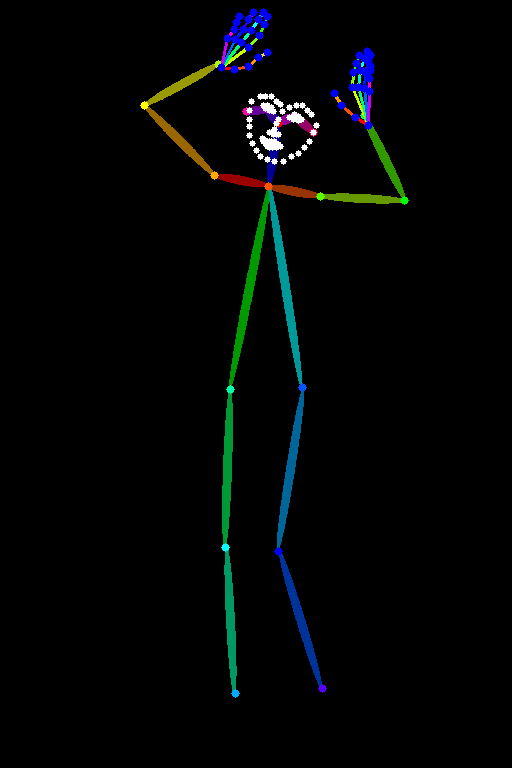 |  |
| openpose_hand | | 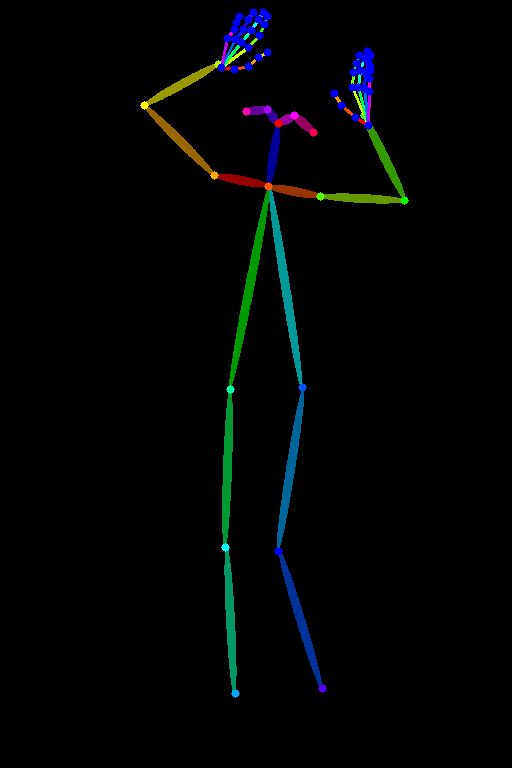 |  |
※お借りした画像:フリー素材ぱくたそ[ https://www.pakutaso.com ]
見ていただくとわかりますが、顔・体・手の3つの要素を使うか使わないかの選択肢になってきますので、用途によって使い分けを行えばいいかと思います。
基本的にはイラストも実写も詳細に判定できるdw_openpose_fullを使えば、プロンプトではなかなか表現できないポーズを取らせることができます。
ちなみに、画像からではなく、棒人間を使ってポーズ指定させるOpenpose Editorなどもあります。
MLSD
直線を抽出するアルゴリズムです。
| Preprocessor | Model |
|---|---|
| mlsd | control_v11p_sd15_mlsd |
| invert (from white bg & black line) |
こちらは実質1種類ですね。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| mlsd |  |  |  |
| invert (from white bg & black line) |  | | なし |
※お借りした画像:フリー素材ぱくたそ[ https://www.pakutaso.com ]
室内など、直線が多い構図に使用すると、破綻していないイラストを生成することができます。ここに先ほど紹介したOpenposeを併用することで、背景が破綻していない人物画が作成できるわけですね。
Lineart
線画抽出アルゴリズムです。使ったことがある人も多いのではないでしょうか。
| Preprocessor | Model |
|---|---|
| lineart_anime | control_v11p_sd15_lineart |
| lineart_anime_denoise | control_v11p_sd15s2_lineart_anime |
| lineart_coarse | |
| lineart_realistic | |
| lineart_standard (from white bg & black line) | |
| invert (from white bg & black line) |
こちらも初期から実装されているものになりますね。modelも2種類あり、通常のモデルとイラスト特化のモデルの2種類が存在します。
2モデル×(invert除いた)5プリプロセッサ=10パターン、というわけでなく、使い分けを行います。
プリプロセッサに「anime」とついていればモデルも「anime」、それ以外はノーマルのモデルを使うといった感じです。ただ、正直モデル差はあまり感じないので、好きにやってもいいかとは思います。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| lineart_anime | |  |  |
| lineart_anime_denoise | |  |  |
| lineart_coarse | |  |  |
| lineart_realistic | |  |  |
| lineart_standard (from white bg & black line) | |  | なし |
| invert (from white bg & black line) | |  | なし |
見ていただいたとおり、どのプリプロセッサを使っても線画はうまく抽出されます。イラストを扱う人なら”lineart_anime_denoise”&”control_v11p_sd15s2_lineart_anime”一択でいいと思います。
「いい構図はできたけど、髪色が気に入らない」みたいなケースで使えるほか、線画を描ける人は色塗りをAIに任せる、みたいなこともできます。
SoftEdge
こちらもLineart同様、線画抽出アルゴリズムです。違いとしては、名前の通り輪郭が気持ち柔らかくなっています(本当か?)。
| Preprocessor | Model |
|---|---|
| softedge_hed | control_v11p_sd15_softedge |
| softedge_hedsafe | |
| softedge_pidinet | |
| softedge_pidisafe |
プリプロセッサは4種類です。見ていきましょう。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| softedge_hed | |  |  |
| softedge_hedsafe | |  |  |
| softedge_pidinet | |  |  |
| softedge_pidisafe | |  |  |
上記の通り、処理後の画像がLineartと大して変わりません。Lineartに比べると細かい線を拾っていますが、それが大きく効くケースは少ないでしょう。
また、softedge_pidinet以外は色の指定があまり効かないケースが多いです。公式もsoftedge_pidinetをおすすめしているのでそういうことでしょう。
Scribble/Sketch
落書きを構図の土台に使う機能です。絵心がなくてもAIが助けてくれます。
| Preprocessor | Model |
|---|---|
| scribble_hed | control_v11p_sd15_scribble |
| scribble_pidinet | |
| scribble_xdog | |
| t2ia_sketch_pidi | |
| invert (from white bg & black line) |
プリプロセッサは4種類です。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| scribble_hed |  |  |  |
| scribble_pidinet | |  |  |
| scribble_xdog | |  |  |
| t2ia_sketch_pidi | |  |  |
| invert (from white bg & black line) | |  | なし |
今回は私の描いたSDキャラを使ってみました。詳細度を上げたイラストを投げると、かなり自分の思い描いているイラストが出力されます。
対して、棒人間のようなイラストを投げると望んだ構図は出ないので、ラフ画が描ける程度の人が使うものと考えたほうがいいですね。
プリプロセッサですが、どれにも一長一短がある感じがします。恐らく、投げるラフイラストによって使い分ける感じになります。詳細に描いたならscribble_pidinet、テキトーならscribble_hedって感じですね。
Segmentation
画像内のオブジェクトを抽出し、分類するアルゴリズムです。
| Preprocessor | Model |
|---|---|
| seg_ofade20k | control_v11p_sd15_seg |
| seg_ofcoco | |
| seg_ufade20k |
プリプロセッサは3種類です。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| seg_ofade20k |  |  |  |
| seg_ofcoco | |  |  |
| seg_ufade20k | |  |  |
※お借りした画像:フリー素材ぱくたそ[ https://www.pakutaso.com ]
使ってみた感じ、seg_ofade20kが一番物体検出が上手でした。生成された画像が処理前と同じテイストにしたいならこれですね。逆にすこしアレンジを加えたいなら他2つが有力になります。
Shuffle
画像をシャッフル(?)して背景のテイストを決める処理を行えます。背景情報のプロンプトを決めるのが面倒な時に便利です。
| Preprocessor | Model |
|---|---|
| shuffle | control_v11e_sd15_shuffle |
どんな処理をしているか知っている人は少ないかもですね。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| shuffle | |  |  |
用途としては絵のテイストを寄せることに特化しています。もう少し例を見てみましょう。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| shuffle | |  |  |
| shuffle |  | |  |
| shuffle |  | |  |
見ていただくとわかる通り、色情報を引き継いで画像を生成しています。特に、一番下の白色はかなり便利で、「白背景で作ろうとすると変な構造物や布が出る」というときに対処できます。
| shuffleあり | shuffleなし |
|---|---|
  |   |
他にも、肌の塗りを変えたいなど様々なことに応用が利くので試してみてください。
Tile/Blur
タイルは画像の構図を変えずに生成したいときに便利です。ブラーはガウスぼかしです。
| Preprocessor | Model |
|---|---|
| blur_gaussian | control_v11f1e_sd15_tile |
| tile_colorfix | |
| tile_colorfix+sharp | |
| tile_resample |
プリプロセッサは4種類です。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| blur_gaussian | |  |  |
| tile_colorfix | | |  |
| tile_colorfix+sharp | | |  |
| tile_resample | | |  |
生成された画像が全く変わっていませんねw
それくらい構図を変えずに生成できるってことです。ダンス動画をAIイラストで制作するときに使っている方もいましたね。
Inpaint
img2imgにもある機能ですね。こちらの方が性能が高い気がするのですが、いかんせんペイント領域の画面が小さいので、使いづらいですね。
| Preprocessor | Model |
|---|---|
| inpaint_global_harmonious | control_v11p_sd15_inpaint |
| inpaint_only | |
| inpaint_only+lama |
3種類あります。lamaのありなしですが、lamaの方が違和感なく画像を生成できます。
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| inpaint_global_harmonious | |  |  |
| inpaint_only | | |  |
| inpaint_only+lama | | |  |
今回は無表情の状態から笑顔にする操作を行いました。inpaint_global_harmoniousはマスクした部分だけでなく、それ以外の部分も変更させることが可能です。今回は行っていませんが、プロンプトに髪色を変えるプロンプトを入れると変化します。
InstructP2P
Instruct(指示する)という意味の通り、任意の画像に指示を入れて書き換えることができる機能です。
| Preprocessor | Model |
|---|---|
| なし | control_v11e_sd15_ip2p |
この機能にはプリプロセッサが存在しません。モデルとプロンプトを使い操作していきます。
| プロンプトの指示 | 入力画像 | 生成された画像 |
|---|---|---|
| 「smile」を追加 | |  |
| 「angry」を追加 | |  |
| 「black hair」を追加 | |  |
上記を見ていただくのが早いと思いますが、プロンプトで内容がかなり変わります。
DepthやLineartのように輪郭を確実に変えずに画像を生成するのではなく、プロンプトによって柔軟に内容を変える感じですので、こちらを好んで使う人もいそうですね。
Reference
「画像1枚でLoraと同じことができる」といえばわかりやすいでしょうか、画像の特徴を拾って生成する画像に反映する機能です。
| Preprocessor | Model |
|---|---|
| reference_adain | なし |
| reference_adain+attn | |
| reference_only |
モデルは無く、プリプロセッサ3種が実装されています。reference_onlyはattn(Attention link)と同義です。つまり、reference_adain+attnは2つのプリプロセッサの掛け合わせになります。
| Preprocessor | 入力画像 | 生成された画像 |
|---|---|---|
| reference_adain | |  |
| reference_adain+attn | |  |
| reference_only | |  |
reference_adainは構図や顔パーツの特徴を抑えている感じがあります。reference_onlyは顔のパーツや雰囲気を捉えていますね。
reference_adain+attnが一番元イラストの特徴を抑えているので、「このキャラの差分イラストをたくさん作りたい」みたいなときに役立ちます。ただし、構図が似通うのでそれが嫌な場合はreference_onlyを使うか、他のControl Typeを併用する必要があります。
Recolor
白黒画像に色を付けることに特化した機能です。SDXLがメインの機能っぽいですが、SD1.5~でも使えます。
情報が少なく、間違っている可能性があります。詳しい使い方を知っている方がいたら、ご連絡ください。
| Preprocessor | Model |
|---|---|
| recolor_intensity | ioclab_sd15_recolor |
| recolor_luminance | sai_xl_recolor_128lora |
| sai_xl_recolor_256lora |
intensityは明暗度、luminanceは輝度を表します。似て非なる概念なので注意。ControlNet上ではあまり気にしなくても大丈夫だとは思います。
目の色を赤色にするために「red eyes」をプロンプトに付け加えました
| Preprocessor | 処理前 | 処理後 | 生成された画像 |
|---|---|---|---|
| recolor_intensity |  |  |  |
| recolor_luminance | |  |  |
今回はPhotoshopで処理前の画像をモノクロ画像にしてからプリプロセッサの処理を掛けましたが、カラー画像を入力画像に使っても動作します。
触ってみた感じ、あまり効果的な使用法は無いかも……
Revision(SDXLのみ対応)
こちらは画像から情報を読み取って、生成する画像に落とし込む機能です。SDXLの機能になるので、SD1.5を使うイラスト勢は重用されないかもしれないです。
| Preprocessor | Model |
|---|---|
| revision_clipvision | なし |
| revision_ignore_prompt |
modelは無いのですが、裏で3.5GB近いアノテータがダウンロードされるので、ストレージが少ない人は注意が必要です。
| Preprocessor | 入力画像 | 生成された画像 |
|---|---|---|
| revision_clipvision | |  |
| revision_ignore_prompt | |  |
revision_clipvisionはプロンプトを参照しながら画像を生成するのに対して、revision_ignore_promptの方は画像情報のみを使って画像を生成するので、かけ離れた画像が生成されることが多かったです。
おそらく、このRevision自体がイラストではなく実写に特化している状態なのではないかと思います。
T2I-Adapter(SDXLのみ対応/現在制作中)
現在詳しい使い方を制作中です。しばらくお待ちください。また、この機能はSDXLのみの対応になっております。
IP-Adapter
画像から情報を読み取って、生成する画像に反映する機能です。Taggerで画像情報を読み取って、プロンプト欄に張り付けて……みたいな作業が無くなります。
| Preprocessor | Model |
|---|---|
| ip-adapter_clip_sd15 | ip-adapter_sd15_plus |
| ip-adapter_clip_sdxl | ip-adapter_xl |
SDXLに対応したモデルも存在します。
| Preprocessor | 入力画像 | 生成された画像 |
|---|---|---|
| ip-adapter_clip_sd15 | |  |
| ip-adapter_clip_sdxl | |  |
生成された画像はパラメータが極端なのでちょっと見栄えが悪いですが、Weightを落とすと見栄えが良くなります。
画像をプロンプト代わりにするので、テキストのプロンプトでは表現できない状況を作るときは便利な感じですね。
ただ、IP-Adapterを使っていて感じるのは、画像生成モデルの画風を殺すケースが多いです。特に色味と描きこみ量が変わるので、それを嫌う場合は使う際に注意が必要です。
結局どの機能を使えばいいの?
これは悩ましいですが、筆者自身は公開用の画像にはDepth・Lineart・Shuffleを多用します。画像生成モデルに強く影響を与えないので、画風や色味を維持できます。Shuffleは白背景を作るときはマストですね。

個人で楽しむときはReferenceやIP-Adapterを使うことが多いですね。コッショリな画像を作るのに便利です。○○先生の画風でこのキャラのこんな構図で……を作ることができます。生成された画像の扱いには注意が必要ですがw
おわりに
ご覧いただきありがとうございます。かなり長い記事なので、チェックが甘くなっていると思います。誤字脱字等ありましたらお気軽にご連絡ください。
ControlNetの実情としては、機能こそ多いけど実用できるのは数種類、という感じです。
どんどん増えているControlNetを活用して、ぜひ自分だけのAIイラストを製作してください!

コメント